
We live in world of big data. The plethora of data gets generated from person’s day-to-day worriedness i.e. banking, social media, insurance, etc. Most of the time this data gets stored in an unstructured way. To perform data wringer on such data is quite a challenging task. We are going to discuss a state-of-the-art technique to solve such challenging problems.
Extracting data from unstructured documents is unchangingly a challenge. Previously we used to have rule-based approaches to tackle such problems. However, due to the nature of the rule-based mechanism, external knowledge source, and manpower is required. To solve such issues, NLP is unchangingly a go-to solution for everyone.
Deep learning has revolutionized the NLP field and to add to it hugging squatter has unchangingly delivered state-of-the-art solutions for multiple problems in NLP. We’re going to discuss one of the SOTA called DONUT.
The DONUT model is proposed in the OCR-free Document Understanding Transformer(DONUT) category by Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park. Donut includes an image Transformer encoder and an autoregressive text Transformer decoder to understand the document. It is widely used for Image classification, form understanding, and visual question answering.

DONUT proposes to solve the pursuit problems.
- CORD (form understanding)
- DocVQA (visual question answering on documents)
- RVL-DIP (document image classification)
In this blog, we will talk well-nigh visual question answering on documents.
DONUT consists of a Transformer based visual encoder and textual decoder modules. In which visual encode extracts relevant features from document and textual decoder convert the derived features into a sequence of sub word to generate a desired output. DONUT doesn’t relay on any of the OCR-module.
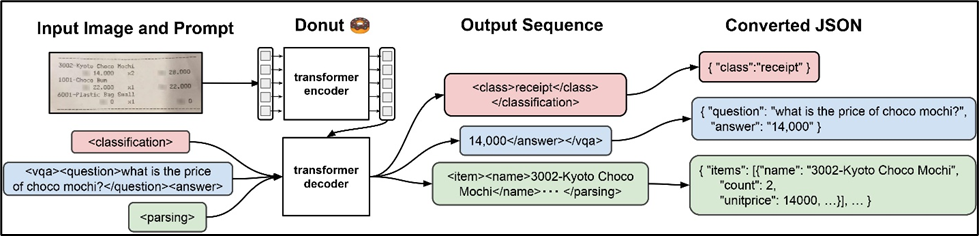
Let us consider one example to understand it better.

This is the sample payslip document(Source Internet). The task is to pericope the information like
- “Employee Name”
- “Total working Day”
- “Final Net pay”
- “Total Deduction”
A possible solution would be to create a template and store the bounding box information for each entity. Such approaches work well when no variegated variations exist. Another possible tideway would be using Layoutlm with finetuning on specific task.
DONUT comes to rescue here with an once pre-trained model, which requires very little or no finetuning.
Let us take a walkthrough of the code. We have used the “Google colab” for ease of exploration.
- To speed up the processing GPU require. Please select processing unit as GPU.
2. Install the packages.
3 . Load the image of payslip. Any Specific image can moreover be used.
4. Load the Process and model
5. Encode image using the Processor
Prepare the image for the model using DonutProcessor.
6. Prediction on the questions
7. Output

Observations
If we unriddle the results, it looks pretty cool. Please alimony in mind pursuit points.
- Document image quality should be upper otherwise OCR (Optical Character Recognition) might be wrong for lower-resolution images.
- Please be specific while drafting the question. Your question should contain a keywords/phrase virtually your answer. It will yield good results.
- It can moreover pericope the value from paragraphs as well. If required field/data exist in paragraph, then asking specific question virtually context yield the results.
Consider the sentence, “. The next meeting of the ACP is scheduled during November 28–30, 2022.”
To pericope the answer, “When is ACP meeting scheduled?” question can be asked.
Conclusion
I specifically tested with variegated images are results are quite breathtaking. Please make sure to use high-resolution images. It will produce much better results.
Please trammels out the full lawmaking here. In subsequent blogs I will share the detail well-nigh finetuning on custom set of data.
Follow me on Linkedin.
Special thanks to Anupam Madhwal for guiding the exploration and Shaksham Kapoor for review and help.
References
Information Extraction with DONUT was originally published in Chatbots Life on Medium, where people are standing the conversation by highlighting and responding to this story.




.webp)



{kind=link}